Perusing the Rails Source Code: 2021 Update
2021 Update
I originally wrote this blog in 2017. Since then, Rails has been through two major upgrades, and I have learned a lot over the past five years.
Because of that, I gave this blog a overhaul that spanned several months in hopes that it can be even more useful to you. This blog still follows the original in spirit, but it includes a lot more specific examples and tricks as well as more helpful resources throughout.
I hope you enjoy it!
The Structure and Purpose of this Post
This blog is intended to help you understand how Rails is structured and how to confidently answer questions about how Rails works.
I’ll show you ways to dig into the code effectively to find what you’re looking for and how to use Git and GitHub as helpful tools for gaining context to the code. Lastly, I’ll share learning strategies that I’ve found helpful for learning complex domains in Rails and ways that you can get involved with contributing to Rails.
The blog is broken into 4 parts:
- The Rails code structure: This section gives an overview of how the code in the Rails repository is structured so that you can know where to look when you have a question about a specific part of Rails.
- Effective ways to dig into the code: This section provides ways to find exactly what you’re looking for when looking for specific methods or behaviors in Rails code.
- Finding Context with GitHub and Git: I find that looking at the code isn’t enough to understand why it’s written the way it is. GitHub and Git provide helpful context like code change summaries, issues, and discussions about the code.
- Learning Strategies for Understanding Rails (Without Overwhelming Yourself): This section is about setting realistic personal expectations and tracking learning effectively (what you know and what you don’t know) so that you can learn without becoming overwhelmed or discouraged. I use these strategies every day both in Rails and at work to learn new things.
Over my years of digging into the Rails source code, I’ve learned that it’s not important to know every detail about Rails, but it’s incredibly helpful to know where to look when you have a question.
Context: Why I Ever Perused Rails (and later gave a talk about it)
When I was a junior engineer, I had two recurring thoughts that conflicted with each other:
- Rails was magic, and I could learn how that magic worked.
- The Rails source code was beyond my comprehension.
These thoughts were a circular battle that I’d experience when getting inspired to learn about how Rails worked (Thought #1) and then dipping my toes into the source code and struggling to understand what I was looking at (Thought #2).
I learned that Thought #2 was a barrier I put up for myself spanning further than Rails and all the way into the professional world. I wasn’t a full time developer yet, and while I had not seen any “professional” Rails apps, I feared that when I did, the code would be beyond my comprehension.
In my first week as a full-time Rails developer, I learned: I was wrong.
The professional code and patterns written in apps to help sustain the business I was working at looked very similar to the code I had written in my hobby apps. Their code was a little more battle tested and complicated, but not beyond my comprehension.
In that week of professional Rails development, Thought #2 lost its traction.
This gave me incentive to jump into Rails. As the weeks went by, I learned some really cool things about Rails and the tools that helped me learn: Ruby, Git, and GitHub. Over time, I had these Aha! moments that helped boost my learning. It was even more exciting when I was able to teach the things I learned to co-workers with decades of programming experience.
Almost exactly a year later, I was at my first RailsConf, on stage and giving a talk about the tricks I learned to understand the Rails code. That’s exactly what I’m excited to share with you! Hopefully you can take the things I learned and apply it to your own Rails learning process.
As you get comfortable with Rails code, you’ll learn more about:
- Ruby - Reading through the source code of Rails, which has been optimized over years, may introduce you new ruby methods, optimizations, meta-programming, and interesting design patterns built.
- Using GitHub and Git effectively - While doing Rails research, you’ll probably learn some new Git commands and some options for commands you already know.
- Open Source projects - Watching the Rails repository gave me a look into how a project can organize releases, plan for major changes, and deprecate functionality. It’s knowledge that doesn’t seem to be taught in class or sold in a book, but it’s useful to know, and through GitHub, you can see it firsthand.
- Magic - Many people say that there’s a log of “Magic” in Rails. They equate the ability do very little to get a project up and running to “Magic”. As you’ll learn when spending time with the code, there is no magic. There’s just a well designed API that does a lot of heavy lifting for users.
- Getting Comfortable with Unfamiliar Code - Learning how to read and understand unfamiliar code set me up for success in my career as a developer.
Part 1: How the Rails code is structured
This sections covers code and design patterns in the Rails source code. Follow along in the Rails repo.
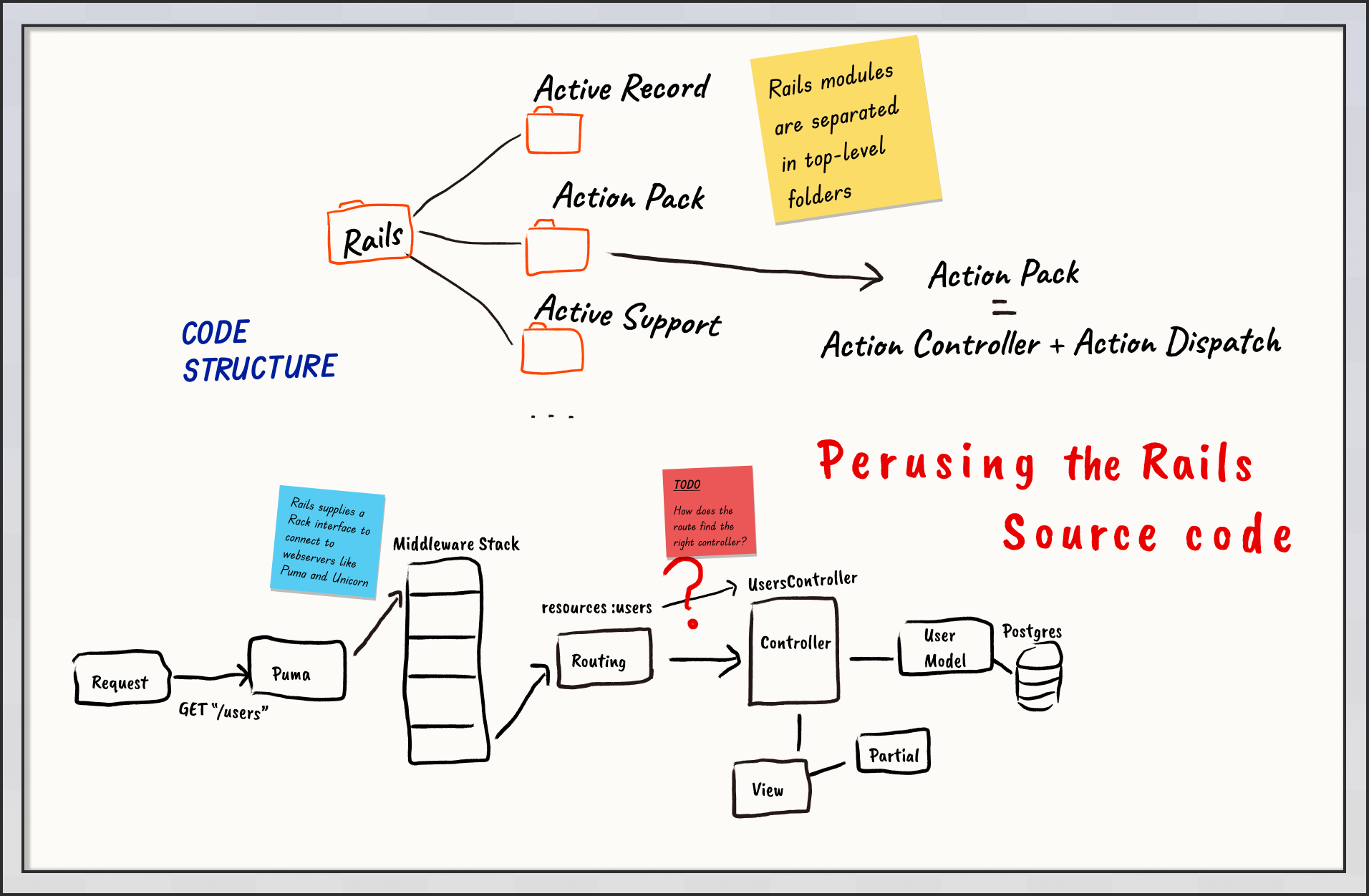
A Top Level View of Rails
The functionality of Rails is broken into separate libraries like Active Record and Active Support. When you step into the Rails code directory, each of these Rails libraries is separated into its own folder.
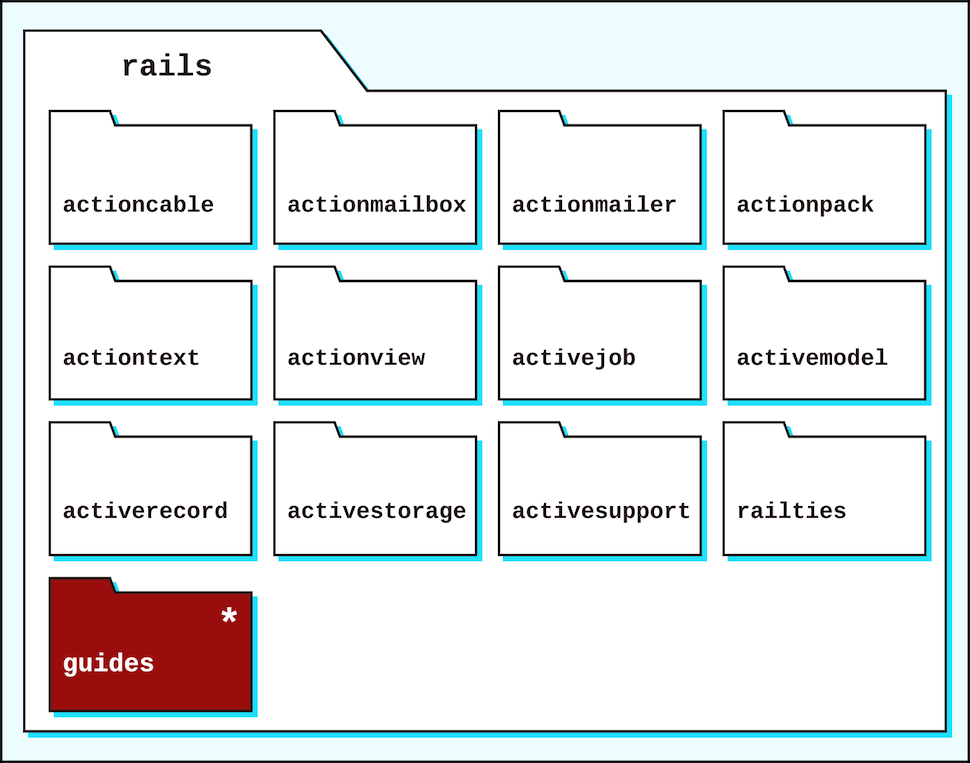
There is also a guides folder at the top level of the repository. This is where the source for guides.rubyonrails.org resides.
Almost each of the Rails libraries is its own gem. This has several benefits:
- We can require only the libraries/frameworks that you need. If you look in the
config/application.rbfile, you will either see arequire rails/allor a list of libraries being required. The rails/all file contains a list of the libraries to require. - It makes developing (and perusing) easier to manage. If you know you want to answer questions about a method or feature, and you know what library it belongs in, then you can have a good idea which folder to start in. Note: I have a description of each library below.
- We can use the gems outside of Rails. Some of the gems can be easily used outside of Rails. For instance, you can use Active Record for database interactions in a non-Rails app, or use the many methods that people love from Active Support in another project.
A Short Description of each Rails Library
Active Record
Active Record, the ORM in Rails, provides a way to communicate with the database. It does this by providing Models to represent database tables and their data, and ineractions like adding/modifying the data. It also provdes Migrations which allow you to update the structure of the database.
Active Model
Active Model provides a model interface outside of Active Record. This allows plain ol’ Ruby objects to behave like an Active Record model.
Action Pack
When we think of web requests, Action Pack is doing the coordination for a request. Inside of Action Pack is the code of Action Controller as well as Routing.
Action Mailer extends Action Pack for controller-like functionality for the mailers.
Action View
Action View takes the instance variables of the controller, coordinates choosing which view file (think .html.erb for example) needs to be used, and compiles it into a response ‘body’ to share with the controller. Even in the case of responding with JSON, Action View plays a part in its compilation.
Action Cable
Action Cable provides a nice way to integrate WebSockets into your Rails app. I’ll admit that I haven’t used Action Cable much (mostly because I haven’t had a need).
Active Job
Active Job provides a Rails interface for dealing with background jobs. It provides a universal job interface despite your queuing library (like Resque or Sidekiq).
Active Support
Active Support provides a ton of extensions to the Ruby language throughout Rails. It has somewhat acted as a testing bed for Ruby features in the past.
Active Storage
Active Storage provides a very nice API for interacting with 3rd party storage API’s like AWS S3 and connecting them to attributes on your models. The structure of the Active Storage source code is interesting, essentially being a Rails app inside of the Rails source code.
Action Mailer
Action Mailer provides you with a way to send emails from within your Rails app, treating them as ‘models’, ‘views’ and ‘controllers’ like a web request.
Action Mailbox
Action Mailbox provides you with a way to receive emails from within your Rails app. Its source code too resembles a Rails app.
Action Text
Action Text is one of the newest modules to Rails, and it provides a nice way to manage ‘rich content’ on the backend of Rails and in the UI through a ‘What you see is what you get’ editor. Its source code too resembles a Rails app.
The Rails Libraries/Frameworks through the view of a Web Request
If we are thinking of Rails through a web request, here’s what it might look like from a Rails library perspective.
Say you have an app running and listening to requests. You go to https://your-app-url.com/posts/12. When that request makes it to your app, here are the steps it will take:
- First, that request will hit your web-server. Think Puma, WEBrick, etc. Your web-server is going to pass that request on to you app.
- The first library involved, Action Pack, will receive the request. Here, it will go through middleware, routing, and make it to the controller, all controlled within Action Pack.
- The controller may involve its friend, Active Record to grab a row from the database and store it in a Post model object.
- Next, it will delegate to Action View to find and compile the right view for the response.
- Action Pack will take the response it has built from the controller, pass it back up and to the web-server to send it off to the user.
If you want a more in depth look at how controllers work to receive a request and build a response, check out my 2020 RailsConf talk, Rebuilding ActionController.
How a Rails library is structured
The Rails libraries each follow the conventional structure of a Ruby Gem. This means that the gems follow these patterns:
- The lib folder contains the library’s code.
- The test folder contains the tests, or the expectations of the code of the library.
- The gemspec file outlines specifications of the gem. This will include the gems that it depends on. For instance, Action View requires erubi to compile .erb files, and Action Pack requires Rack to extend its interface for handling web requests (read more about Rails on Rack here in the guides).
Some other files that I find helpful to review are:
- The README: This is a great place to start to get a summary of the library. Even if you’re familiar with the library, I bet you’ll find some good takeaways from the README.
- The CHANGELOG file: This file contains a summary of recent changes to the library that are noteworthy (like breaking changes, notable additions, and deprecations).
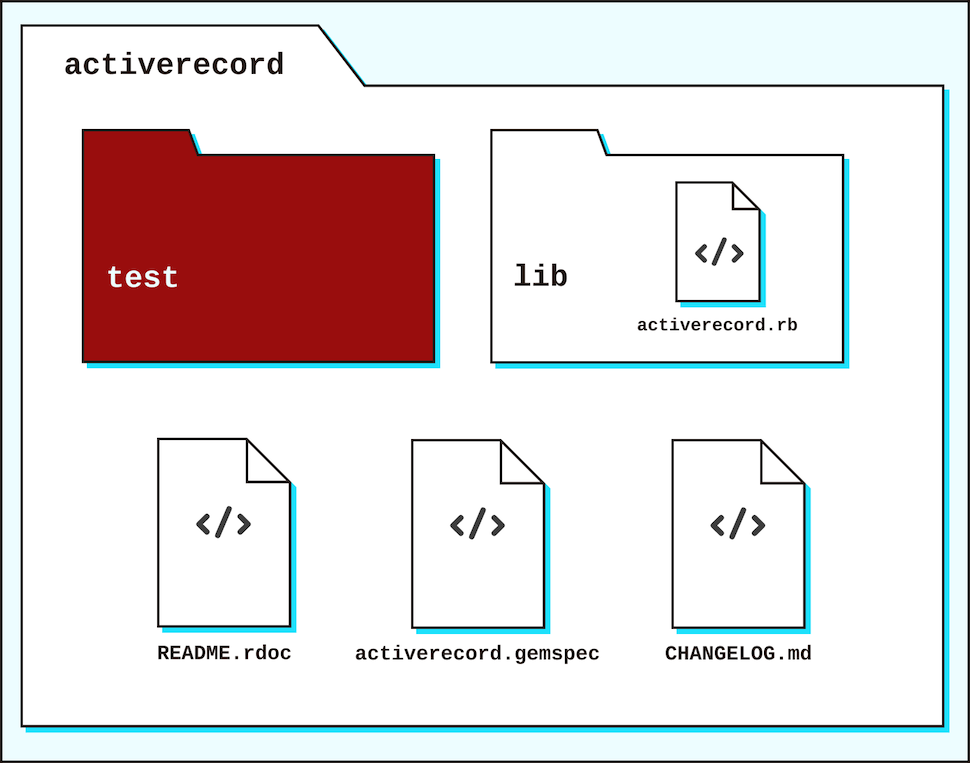
The lib folder
The lib folders holds the functionality of the Rails library. While each Rails library will have completely different classes and modules within them, they each share a similar lib structure at the top level.
The lib/library_name.rb file
The fire level in lib holds a file named after the library. This file is where the library begins when you require it. Because it’s the starting point for the library, it serves as a great place to understand how the library works.
You will see a list of names of the classes and modules in the Rails library and see how they are loaded through eager loading and autoloading. If you are not familiar Eagerloading and Autoloading, this is a great opportunity to learn how it works and see which files are eagerloaded vs. autoloaded in the library.
From a learning perspective, this file gives you at a glance the names of classes or terminology that you’ll see in the code of the library itself. You’ll become more familiar with these names as you spend more time in the code.
module ActionView extend ActiveSupport::Autoload eager_autoload do autoload :Base autoload :Context autoload :Digestor autoload :Helpers . . . end end
lib/library_name folder
This folder will contain the files for the classes and modules of the code. The names that are autoloaded and eager loaded in the lib/«library_name».rb file will correspond to the files in this folder.
helpers/ locale/ renderer/ tasks/ template/ testing/ base.rb buffers.rb cache_expiry.rb context.rb dependency_tracker.rb digestor.rb
lib/library_name/railties.rb file
One file to call out in this folder is the railtie.rb file. The railtie file contains the configuration defaults for the library as well as setup for the initializers and rake tasks for the library.
module ActionView # = Action View Railtie class Railtie < Rails::Engine # :nodoc: config.action_view = ActiveSupport::OrderedOptions.new config.action_view.embed_authenticity_token_in_remote_forms = nil config.action_view.debug_missing_translation = true config.action_view.default_enforce_utf8 = nil config.action_view.image_loading = nil config.action_view.image_decoding = nil config.action_view.apply_stylesheet_media_default = true . . . end end
This file gives you a ton of information on the configuration options available within a library.
libraryname/lib/rails folder
This folder holds the generators for the Rails library. For instance, this is where you will find the generator for Active Record like rails generate migration or rails generate model.
Part 2: Effective ways to dig into the code
With a basic understanding of how the code is structured in Rails, this section goes through strategies that I consider as helpful for familiarizing yourself with the code.
Pre-step: Setting up the Rails Repo to run locally
If you want to run the code locally, you will first need a copy of the Rails source code. If you’re wanting to just peruse the code, then cloning it from GitHub can suffice, but if you want to make changes and run tests, then I recommend following the guides to get the source code set up to test. The tests can allow you to better understand how the code flows and works together.
Once your local repo is set up, you’re ready to start perusing.
The easiest place to start: Read the library README
When available, I like starting with the individual READMEs of the libraries. The README provides a good summary of the functionality and purpose of the library. There’s almost always something to gain from the README, whether it’s an improved perspective of what the library is meant to do or just a tidbit of information that you didn’t know.
Start with what you know: Dig into familiar methods
When digging into code, I find it less effective to dig into code that I’ve never used. I like to start with digging through the modules or methods that I have used and am familiar with.
Doing this, I find new ways of using those methods or modules, and I see what their code is actually doing.
Example: The Controller’s render
As an example, I wanted to better understand how controllers work, so I started with the render method in a controller.
I know that I can tell render to render a specific view (render :show or render "books/edit"), and I expect that I’ll see that view rendered in the browser when I visit that controller action’s endpoint. But I had no idea how how the “rendering” makes it into a response.
Here’s the code for render:
# File actionpack/lib/abstract_controller/rendering.rb, line 28 def render(*args, &block) options = _normalize_render(*args, &block) rendered_body = render_to_body(options) if options[:html] _set_html_content_type else _set_rendered_content_type rendered_format end _set_vary_header self.response_body = rendered_body end
A lot is going on in the render code, but because I know what I expect it to do and what arguments I give it, I can read it and get an idea of what it’s doing. I also learned that the rendered view (rendered_body) gets set onto a response_body of the controller.
Note: If the render code peaks your interest in how controllers work, check out my 2020 RailsConf talk on that subject.
Ways of finding where code lives
In order to dig into the methods and classes you know, you have to know how to find them. Here are three approaches that I like to take:
- Using the docs on api.rubyonrails.org
- Using Ruby’s introspection methods
- Using a “stepping” debugger
Using the Rails API docs to find code
Spread throughout the files of the Rails code, you’ll find documentation.
The documentation in these files is what makes up the docs on the api.rubyonrails.org website. The website allows you to search by method or class, and it provides you with the documentation for the method as well as a quick view of the source code and a link to the code on GitHub.
The API docs site is usually my quickest way of finding source code, unless I already know where the code lives.
Note on APIdock: Lots of people wonder why APIdock isn’t up-to-date. The Rails team is not associated with APIdock, so I don’t rely on it for up to date info. The official API site, api.rubyonrails.org, gets updated with each new Rails version release.
Ruby’s Introspection Methods: At a glance
The documentation can be helpful for straightforward methods, but it can be less useful for methods where the codes is spread across several modules. Code splitting among modules is a common pattern in Rails for more complex methods.
When the documentation doesn’t provide you with what you need, you can use special methods in Ruby to find information on the location and ancestors of a certain method.
I found many of these methods through a blog by Aaron Patterson called “I am a puts debugger”. He shares several tactics that he uses when debugging Ruby using simple puts statements, with some basic examples and some more complex ones.
The method method : find information on a specific method
Ruby has a special method called method that provides you with an object containing info on where a certain method lives, what it looks like, and who it belongs to.
> Post.method(:create) => <Method: Post(id: integer).create(attributes=..., &block) rails/activerecord/lib/active_record/persistence.rb:33>
Here are a few pieces of info that the Method object provides:
- source_location: source_location provides you with the file and line number where the method is defined.
- super_method: If the method calls
super, then super_method provides you with a Method object of the method that it willsuperto. - owner: owner provides you with the class or module name that the method lives in.
- source: source actually provides you with a string of the source code.
Let’s put all this together!
Looking at the Model create method: A single method example
We’ll start simple with the create method. The create method is a good straightforward method to look at. The source location gives you a direct link to the code we’re looking for. At the time I’m writing this, create lives in the Persistence module in Active Record, at line 33.
> create_method = Post.method(:create) => <Method: Post(id: integer).create(attributes=..., &block) rails/activerecord/lib/active_record/persistence.rb:33> > puts create_method.source def create(attributes = nil, &block) if attributes.is_a?(Array) attributes.collect { |attr| create(attr, &block) } else object = new(attributes, &block) object.save object end end
The code itself for create is also pretty straightforward.
Looking at the save method of a model: A multi-modular example
Methods like create are easy to find and understand because the code lives in one place. But, in much of the Rails code, certain methods have their code split throughout Rails modules that encompass the overall method behavior. The save method is an example of this.
With save, the code is spread through different modules of Active Record: one for running validations, one for managing database transactions, all the way up to one actually doing the saving. The code starts in one module and makes its way through the other modules with super.
This means that using source_location will give us the first module location, but it won’t give us the full picture of what save actually does.
This is where we can use the other methods provided by the Method object. They will help us see the modules involved in save and the order that they go through. Below is a little script example of the information we can get from the Method objects.
method_object = Post.new.method(:save) # This loop outputs data on the method and then # moves to its super_method. It does this until # there are no more methods to super into. # # The final method at the end of the loop usually # contains the core functionality of the method. until method_object.nil? owner = method_object.owner location = method_object.source_location source = method_object.source super_method = method_object.super_method puts "#" * 80 puts "\nIn #{owner}: #{location}" puts source if super_method puts "Going from #{owner} to #{super_method.owner}\n\n" end method_object = super_method end ################################################################################ In ActiveRecord::Suppressor: ["rails/activerecord/lib/active_record/suppressor.rb", 43] def save(**) # :nodoc: SuppressorRegistry.suppressed[self.class.name] ? true : super end Going from ActiveRecord::Suppressor to ActiveRecord::Transactions ################################################################################ In ActiveRecord::Transactions: ["rails/activerecord/lib/active_record/transactions.rb", 297] def save(**) #:nodoc: with_transaction_returning_status { super } end Going from ActiveRecord::Transactions to ActiveRecord::Validations ################################################################################ In ActiveRecord::Validations: ["rails/activerecord/lib/active_record/validations.rb", 46] def save(**options) perform_validations(options) ? super : false end Going from ActiveRecord::Validations to ActiveRecord::Persistence ################################################################################ In ActiveRecord::Persistence: ["rails/activerecord/lib/active_record/persistence.rb", 538] def save(**options, &block) create_or_update(**options, &block) rescue ActiveRecord::RecordInvalid false end
The output provides us with the modules and the order that they run in for the save method of a model. We can see that save goes through Suppressor, Transactions, Validations, and then it finally lands in Persistence.
I find this to be a quick and clean way to find all of modules and details for a method and I’ve stored it in a sandbox Rails app for ease-of-use.
Step into the code with a Debugger
When I find certain areas of code to be hard to read, I like to use Pry-Byebug. Pry-Byebug extends the abilities of pry to include Byebug’s features of stepping through code as it is running.
36: 37: class Comment < ActiveRecord::Base 38: belongs_to :post 39: end 40: => 41: binding.pry 42: post = Post.create! 43: post.comments << Comment.create! 44: 45: assert_equal 1, post.comments.count 46: assert_equal 1, Comment.count [1] pry(main)>
For a quick run through of how to step through code with Byebug, check out the Debugging section of the Ruby on Rails guides.
Create a minimal Rails example with the Rails Bug Report Templates
The Rails team provides several bug report templates, and they’re perfect for digging into a particular method or section of Rails.
For an example, let’s look at the Active Record main template.
# frozen_string_literal: true require "bundler/inline" gemfile(true) do source "https://rubygems.org" git_source(:github) { |repo| "https://github.com/#{repo}.git" } gem "rails", github: "rails/rails", branch: "main" gem "sqlite3" end require "active_record" require "minitest/autorun" require "logger" # This connection will do for database-independent bug reports. ActiveRecord::Base.establish_connection(adapter: "sqlite3", database: ":memory:") ActiveRecord::Base.logger = Logger.new(STDOUT) ActiveRecord::Schema.define do create_table :posts, force: true do |t| end create_table :comments, force: true do |t| t.integer :post_id end end class Post < ActiveRecord::Base has_many :comments end class Comment < ActiveRecord::Base belongs_to :post end class BugTest < Minitest::Test def test_association_stuff post = Post.create! post.comments << Comment.create! assert_equal 1, post.comments.count assert_equal 1, Comment.count assert_equal post.id, Comment.first.post.id end end
The script does a few things:
- It provides an inline “Gemfile” so that you can specify the gems you want to use and their respective locations. This is really helpful if you want to use a local version of a gem. (See the “Specifying the Gem Location in a Gemfile” card below)
- The Active Record script sets up a database by connecting to it and providing schema and model definitions.
- It provides a simple test case that you can modify. I often set up what I want to look at and throw a
binding.pryto play around with it interactively.
I use these scripts to quickly test out certain Rails methods, and I often use my local repo as the source of the Rails gem so that I can dig through the code a little easier.
Specifying the Gem Location in a Gemfile
Bundler allows you to specify the location of a gem, rather than grabbing the gem from rubygems.org.
Using path
I often like to use my local Rails repo to debug. In order to use it in a script, I can specify the gem as:
gem "rails", path: "../path/to/rails"
Using git
You may notice that the script uses GitHub for the Rails source.
git_source(:github) { |repo| "https://github.com/#{repo}.git" } gem "rails", github: "rails/rails"
This allows you to use the git repository of Rails, rather than limiting you to versions in rubygems.org.
The Bundler docs show you several ways to use a git repo in your Gemfile, including how to use a branch or specific commit.
Part 3: Finding Context with GitHub and Git
Reading the code and tests doesn’t always give enough context to why the code works a certain way. In these cases, I find both git and GitHub to be helpful for providing additional context.
These days, I lean towards using GitHub because it’s easier and quicker to use. Still, its nice to know how to find things with Git, so I’ll show some git alternatives to GitHub features.
Find the commits for code changes with Blame
The blame feature in both Git and GitHub allow you to connect a line of code with the commit that introduced the code. I use Blaming to answer the question, “Why was this behavior introduced?”, and I typically go about it in this way:
- Find the commit that introduced the behavior and review it.
- Find the Pull Request for the commit if there is one. I review the description, comments, and the collection of commits. This helps me to understand how the committer and reviewers thought about the changes made.
- Find the GitHub Issue for the pull request if there is one. Many PR’s are opened to address a certain issue. If that’s the case, then the issue often provides a clear picture of the original problem.
- Follow any other breadcrumbs left in the pull request or issue, like mentions of other issues.
To start, GitHub provides a Blame view that shows you the last commit for each line in the file.
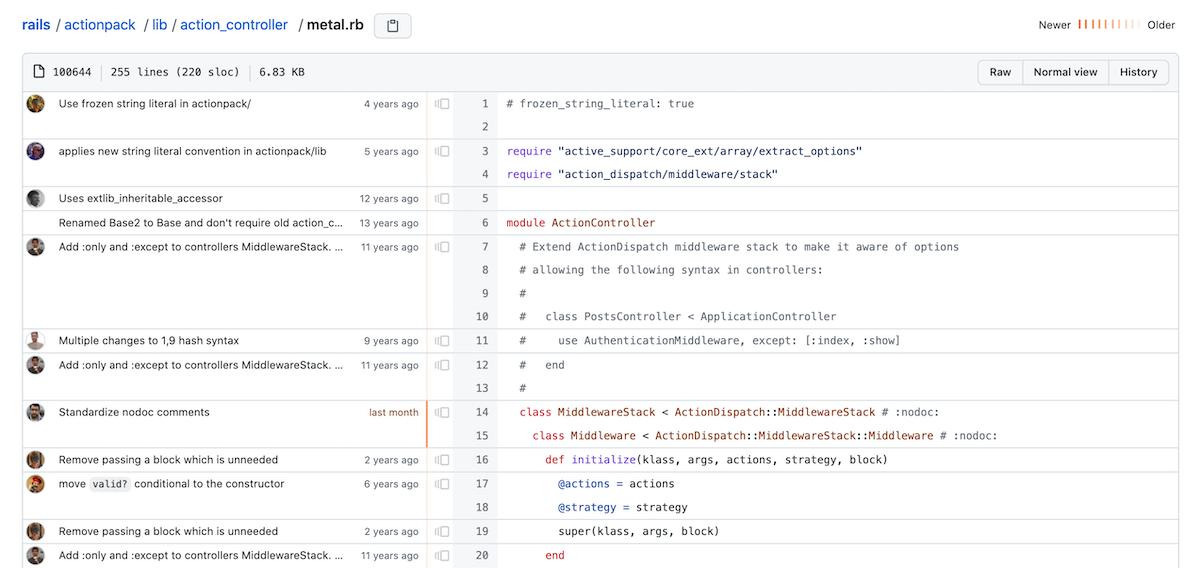
This will give us the code view with the commits to the left of each line of code. If the code isn’t updated often, this may give you exactly what you’re looking for. In cases where where the code has been slightly modified over time, there can be a level of obscurity to finding original changes.
Thankfully, we can use the Reblame feature in GitHub.
Look at the past code with the Reblame button
In the Blame view of GitHub, on each line of code you’ll see this icon:

If you click on the icon of a specific line of code, GitHub will rewind the blame view for the file and show you what the code looked like prior to that commit.
In the example above, I can click through the re-blames for the other lines of code for that method or test and I will eventually find the original commit.
Searching for the PR and possible issue for the commit
GitHub provides a URL for every commit in the Rails git repository.
On the commit page, in the bottom left of the commit description, I can see any the related PR number next to the main branch specifier. There, I can dig into other commits related to the PR as well as issues that the PR may reference.

Finding and reading the pull request (and issue if there is one) can be incredibly valuable. Often, there will be conversations about trade-offs and the benefits of certain approaches. There will also be feedback from core Rails members who know the code-base very well.
Note: Typically you can search by the commit hash to find the commit and its PR in the search bar. It seems like this feature is broken after the default branch switch from “master” to “main” in the Rails repo.
Using Git to Gain Context
It is possible to do all of the same things we did in GitHub with Git. I find these handy to know especially in the older parts of the code like Active Record that may precede the days of Pull Requests. In Git, there is a history of the Rails code base taking you all the way back to 2004.
commit db045dbbf60b53dbe013ef25554fd013baf88134 Author: DHH <david@loudthinking.com> Date: Wed Nov 24 01:04:44 2004 +0000 Initial git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
Back then, the code consisted of Action Mailer, Action Pack, Active Record, and Railties.
~/rails $ ls actionmailer actionpack activerecord doc railties
That is almost 20 years of commit history that we can sift through. Here are a few helpful git commits for finding what you need.
git blame
Git blame gives us the latest commit for each line of code in a file, just like the view in GitHub.
~/rails $ git blame -c actionpack/lib/action_dispatch/http/request.rb b0d0c9f40df (Akira Matsuda 2017-10-21 14)require "action_dispatch/http/url" 628e51ff109 (Xavier Noria 2016-08-06 15)require "active_support/core_ext/array/conversions" 0a9bc591e78 (Rick Olson 2007-11-29 16) 319ae4628f4 (Joshua Peek 2009-01-27 17)module ActionDispatch 529136d670c (Aaron P. 2015-09-04 18) class Request 529136d670c (Aaron P. 2015-09-04 19) include Rack::Request::Helpers 92f49b5f1eb (José Valim 2010-01-16 20) include ActionDispatch::Http::Cache::Request 92f49b5f1eb (José Valim 2010-01-16 21) include ActionDispatch::Http::MimeNegotiation 92f49b5f1eb (José Valim 2010-01-16 22) include ActionDispatch::Http::Parameters 31fddf2ace2 (José Valim 2010-01-21 23) include ActionDispatch::Http::FilterParameters 92f49b5f1eb (José Valim 2010-01-16 24) include ActionDispatch::Http::URL 456c3ffdbe3 (Andrew White 2017-11-15 25) include ActionDispatch::ContentSecurity Policy::Request 90e710d7672 (Julien G. 2020-11-14 26) include ActionDispatch::PermissionsPolicy::Request 529136d670c (Aaron P. 2015-09-04 27) include Rack::Request::Env 293bb02f913 (Pratik Naik 2008-12-23 28) 628e51ff109 (Xavier Noria 2016-08-06 29) autoload :Session, "action_dispatch/request/session"
The default blame can be less effective when a file has add indention/spacing changes, but you can provide the -w option to ignore white-space changes.
git log -S | A way to search commits
git log provides you with a way to search commits by the changes they made. git log -S "search query" returns any commits that have made an addition or deletion similar to the the code snippet you pass in. This is helpful for when a line a code has been moved around or changed many times.
It can be also be helpful if you want to see every time a certain class was added/removed from code. For instance, if I want to see commits that “required” Active Support Concerns in Rails, I can run:
$ git log -pS 'require "active_support/concern"'
This will give me a list of commits that include require "active_support/concern".
There are a few options I like to use with -S that make the output of git log more useful:
- –patch or -p: The patch option includes the changes that were made in the commit
- –pickaxe-all: When -S finds a change, it shows only the files that contain the change. With this option, it will show all the changes in that commit. Usually if other files are changed in a commit, those changes are relevant.
git bisect | Find where an issue was introduced
Git bisect is an incredibly helpful tool for finding when a specific behavior was introduced. In order to use it, you’ll want to be able to reproduce the behavior and a time/version when that behavior acted differently. For instance if you noticed that a specific behavior changed between two versions of Rails, you could use git bisect to find the commit that introduced the changed behavior.
Here’s a simple example to show how git bisect works.
Finding the introduction of excluding in Active Record
In Rails 6, an exclude method was added to ActiveRecord::Relation, so that records could be excluded from a query. Here’s a script to reproduce the method:
# frozen_string_literal: true require "bundler/inline" gemfile(true) do source "https://rubygems.org" git_source(:github) { |repo| "https://github.com/#{repo}.git" } gem "rails", path: "../rails" # replace with the path to your local Rails repo gem "sqlite3" end require "active_record" require "minitest/autorun" require "logger" # This connection will do for database-independent bug reports. ActiveRecord::Base.establish_connection(adapter: "sqlite3", database: ":memory:") ActiveRecord::Base.logger = Logger.new(STDOUT) ActiveRecord::Schema.define do create_table :posts, force: true do |t| t.text :title end end class Post < ActiveRecord::Base end class BugTest < Minitest::Test def test_excluding post = Post.create!(title: "I'm Included") other_post = Post.create!(title: "Please don't include me!") assert_equal [post], Post.excluding(other_post) end end
We can see from the Pull Request that it was added on February 16th 2021. Let’s find a commit from before this PR (say from the day before, February 15th, and let’s pretend we don’t know when excluding was added.
➜ rails git:(main) ✗ git log --oneline --before 2021-02-15 -n 1 be7185bbae Merge pull request #41436 from santib/fix-active-storage-sharpening-docs
We know that the method exists on the main branch, and we know that it does not exist in the repo from the point of that Feb. 15th commit, be7185bbae. We can use Git bisect between these two points, and it should lead us to the commit from the PR, 690fdbb2b96b08f53e9de99bb42e79a634f623ee.
Here are the steps to take to use git bisect here.
- Start in the
mainbranch of Rails. - Run
git bisect start- Git Bisect will do a binary search to find which commit introduced the behavior. Here we are starting the bisect, and we first have to label the branches. - Run
git bisect old be7185bbae- We are telling Git Bisect that at the point of that commit, the old behavior (or the method not existing) is on the repo. - Run
git bisect new- We are telling Git Bisect that the new behavior is in the latest commit of the current branch,main. This will start Git Bisect and it will check out a commit in the middle the commits for new and old. - Run the test script in a separate terminal and see the results - If the script passes, label it by running
git bisect new(we’re saying it shows the new behavior). If it fails, rungit bisect old. Now Git Bisect will find another midpoint to test. - Redo the previous step until it finds the commit.
Here is what my output looked like, eventually leading me to the commit from the PR:
➜ rails git:(main) ✗ git bisect start ➜ rails git:(main) ✗ git bisect old be7185bbae50a8b74b91f4ec1b848e8b5f496ba5 ➜ rails git:(main) ✗ git bisect new Bisecting: 1019 revisions left to test after this (roughly 10 steps) [79a00fd11c6a93d2a413b4d8bfb8675d5f122844] Merge pull request #42276 from georgeclaghorn/activestorage-timestamp-precision ➜ rails git:(79a00fd11c) ✗ git bisect new Bisecting: 508 revisions left to test after this (roughly 9 steps) [a27c9eeddb19eaabf2e6d808152b18d5ca17736f] Merge pull request #41917 from jbampton/fix-ie-typos ➜ rails git:(a27c9eeddb) ✗ git bisect new Bisecting: 254 revisions left to test after this (roughly 8 steps) [043184d903188b9485afcfd3c551f500a5307918] Fix end alignment ➜ rails git:(043184d903) ✗ git bisect new Bisecting: 126 revisions left to test after this (roughly 7 steps) [64ca6f608ec4456805fd7f40c8d6e0009e286415] Avoid extra `BindParam` allocation to generate placeholder in queries ➜ rails git:(64ca6f608e) ✗ git bisect new Bisecting: 63 revisions left to test after this (roughly 6 steps) [3875e07f3cecf20dc1995e162a0187235881c5a3] Simplify `formmethod` checks on `button_to` for non-GET/POST handling ➜ rails git:(3875e07f3c) ✗ git bisect new Bisecting: 31 revisions left to test after this (roughly 5 steps) [37303ea499c44fde9c552a701fe3c34cdedba0e5] Avoid having to store complex object in the default translation file ➜ rails git:(37303ea499) ✗ git bisect new Bisecting: 15 revisions left to test after this (roughly 4 steps) [48effc7587d059a39c8ab02514ad948849a25627] Merge pull request #41372 from Shopify/ar-relation-async-query ➜ rails git:(48effc7587) ✗ git bisect new Bisecting: 6 revisions left to test after this (roughly 3 steps) [a642b7c02bd99aa7f1be227ab3f778cb2fa72f5f] Merge pull request #41450 from jonathanhefner/sms_to-improve-api-doc ➜ rails git:(a642b7c02b) ✗ git bisect old Bisecting: 3 revisions left to test after this (roughly 2 steps) [d79f3b2a37a1e7dededefd5b0d6822f0d4f5a037] Merge pull request #41439 from GlenCrawford/feature/active_record_query_methods_excludes ➜ rails git:(d79f3b2a37) ✗ git bisect new Bisecting: 1 revision left to test after this (roughly 1 step) [0f09dfca363410f51f6f60787a0e497ee66cdd13] Guard against using VERSION with db:rollback (#41430) ➜ rails git:(0f09dfca36) ✗ git bisect old Bisecting: 0 revisions left to test after this (roughly 0 steps) [690fdbb2b96b08f53e9de99bb42e79a634f623ee] Implemented `ActiveRecord::Relation#excluding` method. ➜ rails git:(690fdbb2b9) ✗ git bisect new 690fdbb2b96b08f53e9de99bb42e79a634f623ee is the first new commit commit 690fdbb2b96b08f53e9de99bb42e79a634f623ee Author: Glen Crawford <glencraw4d@gmail.com> Date: Sun Feb 14 19:41:49 2021 +1100 Implemented `ActiveRecord::Relation#excluding` method. This method excludes the specified record (or collection of records) from the resulting relation. For example: `Post.excluding(post)`, `Post.excluding(post_one, post_two)`, and `post.comments.excluding(comment)`. This is short-hand for `Post.where.not(id: post.id)` (for a single record) and `Post.where.not(id: [post_one.id, post_two.id])` (for a collection). activerecord/CHANGELOG.md | 22 +++++++ activerecord/lib/active_record/querying.rb | 2 +- .../lib/active_record/relation/query_methods.rb | 45 ++++++++++++++ activerecord/test/cases/excluding_test.rb | 71 ++++++++++++++++++++++ 4 files changed, 139 insertions(+), 1 deletion(-) create mode 100644 activerecord/test/cases/excluding_test.rb
If you want a more thorough rundown of Git Bisect, check out this part of Eileen’s Contributing to Rails talk to see how to use it when triaging Rails issues.
Part 4: Learning Strategies for Understanding Rails (Without Overwhelming Yourself)
Rails is a very large and often complex codebase. Because of that, I find it’s easier to dig into the code with a specific purpose. Here are a few ways I do that.
Framing Learning Goals (and Expectations)
I have a lot of experience using Active Record and no experience using Action Cable. With the context I have in Active Record on how to use it and what I expect it to do, that means I’m going to have more success digging into the Active Record code and especially the methods I’ve used before.
With Action Cable, if I start with the goal of understanding the Action Cable Internals, I may be setting myself up for failure (or at least a headache). Here, I’d be better off framing and focusing my Action Cable goals on learning how to use it, and once I’ve accomplished that goal, I can dig deeper.
To be able to consistently learn Rails and other source projects, I think it’s very important to size up my goals and expectations next to the amount of mental energy and time I’m able to put in. This helps me set realistic and achievable learning goals.
Ask Small Questions
My favorite system for learning a complex subject is to break it down into several small questions. For instance, if I wanted to dig into the question of “How does Active Record work?”, I may break it down into a list of questions:
- How does Active Record connect to a Database?
- How does Active Record build a query?
- How does
Person.find(id)work?- Where does the code for
<<model_class>>.find(id)live?
- Where does the code for
- How does
Person.find(id).friendsreturn an association?
- How does
- What is Arel?
- What is the difference between Active Model and Active Record?
- How are the two related?
This gives me essentially a Question Task List to work from (or the opposite of TIL, TIDK-Today I Don’t Know). Some questions have their own smaller, specific questions. I go through this list answering questions and adding new ones until I have confidently answered my big question.
What’s nice about a list like this is that I can dedicate 15 minutes to digging into one question, reasonably answer it, and feel confident that I did something productive.
In fact, this is how I did my research for my 2020 RailsConf talk on ActionController.
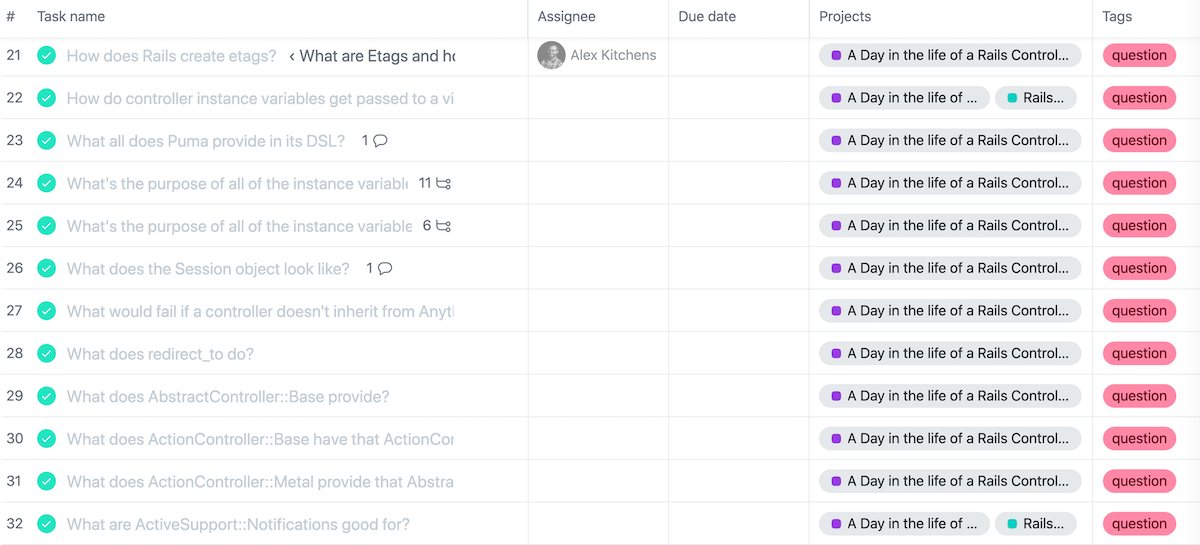
Follow along with the repo in GitHub
Read the issues and pull requests that come into GitHub. This will help you know which issues and features are currently being addressed in Rails.
Strategy: Watch the Repo + Unsubscribe from Irrelevant Issues
Watching the Rails repo can mean a lot of daily notifications. I have found a way to counteract the number of notifications is to unsubscribe from any issue or pull request that I’m not interested. This can significantly cut down on the daily notifications.
Also, don’t be afraid to call bankruptcy and clear all notifications if they become too much. 🤷♂️
Reading Along Gets Easier, Over Time
There’s a lot of information to be gained from GitHub, but at first, it can be hard to follow pull requests and commits. I read through many PRs and issues initially with glazed eyes, but from time to time, I’d find a takeaway. The more I did this, and the more I dug into the code, the more takeaways I would find.
Take Advantage of GitHub Labels and Milestones
When looking at pull requests and issues, you can look at what’s familiar to you by taking advantage of the labels in GitHub. In the Issues/PR trackers, you can filter by libraries. I also like to search for a method’s name to see the issues and PR’s related to it.
If you want to keep up with the Rails releases and see some of the changes that will be going into them, you can use the milestones in the issues tracker. Here, you’ll find open PR’s and issues that are planned to be completed for the next releases.
Reproduce an issue
Many times an issue is opened explaining a problem in Rails, but it may not have a reproduction script. Adding a reproduction script is a great way to become comfortable with the different libraries of Rails and it is very helpful to the Rails team. Trying to reproduce an issue with a bug template report gives you a way to play with methods that you may not use every day. If you can reproduce it with a script, comment on the issue saying that you were able to reproduce it and share the script. An easy way to get a shareable copy of the script is with the Gist gem.
Summary: A Simple “Where to Start” Checklist
If I’ve intrigued you to peruse the Rails source code, here are some initial steps you can take:
- Read the Ruby on Rails guides. Even if you’ve read parts of it before, give it a full skim.
- Read the README’s to each library.
- Look into some of the methods you use often, using the Ruby methods I outlined.
- Try to understand a full feature of one of the libraries:
- Read its code and read the code of other areas it depends on. For instance, cookies depend on MessageVerifier and MessageEncryptor from Active Support.
- If the feature is small enough, read all of the logs from
git log --patch --reverse - Search for it in the Rails issue tracker on GitHub and read open and closed PR’s and issues.
- Follow along with the repository in GitHub.
It’s not all glamorous, but it is worthwhile.
Additional Resources
This learning process would not have been so easy without the helpful resources provided by other people in our community. Here are several of them that I’ve found incredibly useful throughout my learning process.
- I am a puts debugger - Aaron Patterson: He has a lot of easy but useful debugging tips for a variety of different problems.
- Ruby Debugging Magic Cheat Sheet - Richard Schneeman: In a similar vein, Schneems has some additionally good debugging takeaways.
- Demystifying Contributing to Rails - Eileen Uchitelle: It took me several days to get through this talk because she goes over so many helpful things, and I kept getting distracting by wanting to try them. This talk was so helpful, that I somewhat purposefully wrote it to be a prequel to that talk.
- RailsConf 2018: Your first contribution (and beyond) by Dinah Shi: If you want to try contributing to Rails, this is a definite watch. She lays out ways that you can get started as well as resources that helped her with her first contributions.
- RailsConf 2018: Re-graphing The Mental Model of The Rails Router - Vaidehi Joshi: This talk goes through how a request hits rails and make it through the router. This talk is fantastic, and it can give you good understanding of the web-server, middleware, Rails routing. She along with some others gave a similar talk the next year that give additional information.
- RailsConf 2020 - Rebuilding ActionController - me: I gave this talk in 2020 on how to reason about ActionController. It’s intentionally meant to complement Vaidehi Joshi’s talk and where it left off.
- Eileen’s System Test Pull Request: Check out Eileen’s pull request for adding system testing to rails. Reading through the conversation on her Pull Request and reading through each commit from the beginning gives you a good look into how a Rails feature is added. The commits are all still there instead of being rebased, so you can see her thinking process as it’s built out. Then watch her talk from RailsConf right before mine where she discusses what it was like to add a feature to Rails, the good and the bad.
- Rails Boot Process - Xavier Noria: Xavier talks about what goes on in the Rails boot process, and it’s a good introduction on what all Rails does when it starts up.
Keeping Up With Rails (Without Wearing Yourself Out)
Watching the Rails repository can be exhausting. Here are a few places to find whats going on in Rails without having to read every issue and pull request:
- This Week in Rails: This is a newsletter written weekly by the Rails team consisting of interesting commits, pull requests and more from Rails.
- Release Notes: The Release notes are a great way to stay up to date with the important changes that happen. They link to the pull requests for the changes, so you can do some extra digging if you want.
Happy Digging
I hope you found some good takeaways, and I hope I’ve inspired you to dig into Rails or your favorite open source project! If you liked the information that I provided you, and would like to connect, feel free to reach out on LinkedIn or email me.
A Big Thank You to Sage Griffin
Sage Griffin gave me a lot of insight and motivation while writing my original talk, as well as helping me learn more about and get comfortable with the Rails internals and even Rust. 😄 I am very happy to have them as a great friend and mentor.
